

Oric Lawson
Viernes por la tarde, el proyecto OpenZFS pecho Versión 2.1.0 de nuestro sistema de archivos favorito eterno «Es complicado pero vale la pena». La nueva versión es compatible con FreeBSD 12.2-RELEASE y posteriores, y con los kernels de Linux 3.10-5.13. Esta versión presenta varias mejoras generales de rendimiento, así como algunas características completamente nuevas, principalmente dirigidas a organizaciones y otros casos de uso muy avanzados.
Hoy, nos centraremos en la característica más importante que agrega OpenZFS 2.1.0: la topología dRAID vdev. dRAID ha estado en desarrollo activo desde al menos 2015 y alcanzó el estado beta cuando integrado En OpenZFS master en noviembre de 2020. Desde entonces, se ha probado exhaustivamente en varias de las principales tiendas de desarrollo de OpenZFS, lo que significa que la versión actual está «fresca» en condiciones de producción, no «nueva» como no se ha probado.
Descripción general de RAID distribuido (dRAID)
Si ya pensaba que la topología ZFS era un archivo compuesto Asunto, prepárate para volar tu mente. RAID distribuido (dRAID) es una topología vdev completamente nueva que encontramos por primera vez en una presentación en la OpenZFS Dev Summit 2016.
Al crear un vdev dRAID, el administrador especifica el número de datos, paridad y sectores de repuesto activo para cada tira. Estos números son independientes del número de discos físicos en vdev. Podemos ver esto en la práctica en el siguiente ejemplo, que se extrae de conceptos básicos de dRAID documentación:
root@box:~# zpool create mypool draid2:4d:1s:11c wwn-0 wwn-1 wwn-2 ... wwn-A
root@box:~# zpool status mypool
pool: mypool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
draid2:4d:11c:1s-0 ONLINE 0 0 0
wwn-0 ONLINE 0 0 0
wwn-1 ONLINE 0 0 0
wwn-2 ONLINE 0 0 0
wwn-3 ONLINE 0 0 0
wwn-4 ONLINE 0 0 0
wwn-5 ONLINE 0 0 0
wwn-6 ONLINE 0 0 0
wwn-7 ONLINE 0 0 0
wwn-8 ONLINE 0 0 0
wwn-9 ONLINE 0 0 0
wwn-A ONLINE 0 0 0
spares
draid2-0-0 AVAILTopología Dredd
En el ejemplo anterior, tenemos once discos: wwn-0 A través de wwn-A. Creamos un vdev draID con 2 dispositivos de paridad, 4 dispositivos de datos y 1 dispositivo de respaldo por cinta, en lenguaje condensado, draid2:4:1.
Aunque tenemos once discos en total en un archivo draid2:4:1, solo se utilizan seis en cada barra de datos, y uno en cada barra físico – físico – cinta. En un mundo de aspiradoras perfectas, superficies sin fricción y gallinas bola, la disposición en el disco draid2:4:1 Se verá así:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a |
| s | s | s | Dr | Dr | Dr | Dr | s | s | Dr | Dr |
| Dr | s | Dr | s | s | Dr | Dr | Dr | Dr | s | s |
| Dr | Dr | s | Dr | Dr | s | s | Dr | Dr | Dr | Dr |
| s | s | Dr | s | Dr | Dr | Dr | s | s | Dr | Dr |
| Dr | Dr | . | . | s | . | . | . | . | . | . |
| . | . | . | . | . | s | . | . | . | . | . |
| . | . | . | . | . | . | s | . | . | . | . |
| . | . | . | . | . | . | . | s | . | . | . |
| . | . | . | . | . | . | . | . | s | . | . |
| . | . | . | . | . | . | . | . | . | s | . |
| . | . | . | . | . | . | . | . | . | . | s |
Efectivamente, Dredd lleva el concepto de RAID de «paridad diagonal» un paso más allá. RAID5 no fue la primera topología de paridad RAID; fue RAID3, en la que la paridad se encontraba en un disco duro, en lugar de distribuirse por toda la matriz.
RAID5 eliminó la unidad de paridad de disco duro y, en su lugar, distribuyó la paridad en todos los discos de matriz, lo que proporcionó escrituras aleatorias mucho más rápidas que RAID3 conceptualmente más simple, porque no impidió cada escritura en un disco de paridad de disco duro.
dRAID toma este concepto, distribuir la paridad en todos los discos, en lugar de agregarlo todo en uno o dos discos duros, y lo extiende a spares. Si el disco falla en dRAID vdev, los sectores de paridad y los datos que viven en el disco muerto se copian en un sector o sectores de repuesto reservados para cada cinta afectada.
Tomemos el gráfico simplificado anterior y veamos qué sucede si sacamos un disco de la matriz. La falla inicial deja lagunas en la mayoría de los conjuntos de datos (en este diagrama simplificado, líneas):
| 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | a | |
| s | s | s | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | s | Dr | s | Dr | Dr | Dr | Dr | s | s | |
| Dr | Dr | s | Dr | s | s | Dr | Dr | Dr | Dr | |
| s | s | Dr | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | Dr | . | s | . | . | . | . | . | . |
Pero cuando usamos resilver, lo hacemos con la capacidad de reserva reservada previamente:
| 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | a | |
| Dr | s | s | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | s | Dr | s | Dr | Dr | Dr | Dr | s | s | |
| Dr | Dr | Dr | Dr | s | s | Dr | Dr | Dr | Dr | |
| s | s | Dr | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | Dr | . | s | . | . | . | . | . | . |
Tenga en cuenta que estos gráficos son simplificado. La imagen completa incluye grupos, segmentos y filas en los que no intentaremos entrar aquí. El diseño lógico también se baraja aleatoriamente para distribuir las cosas de manera uniforme entre las unidades según el desplazamiento. Se anima a los interesados en los detalles más pequeños a echar un vistazo a estos detalles. Suspensión En el código original commit.
También vale la pena señalar que dRAID requiere anchos de banda estáticos, no los anchos dinámicos que admiten los vdevs RAIDz1 y RAIDz2 tradicionales. Si usamos discos 4kn, el archivo. draid2:4:1 Un vdev como el que se muestra arriba requeriría 24 KB en disco por bloque de metadatos, mientras que un vdev RAIDz2 convencional de seis anchos solo necesita 12 KB. Esta discrepancia empeora cuanto mayores son los valores d+p Obtener draid2:8:1 ¡Requeriría la friolera de 40 KB para el mismo bloque de metadatos!
Por esta razón, la special El asignador de vdev es muy útil en grupos con dRAID vdevs, cuando hay un grupo con él. draid2:8:1 y tres de ancho special Necesita almacenar un bloque de metadatos de 4 KB, lo hace en solo 12 KB en un archivo special, en lugar de 40 KB en un archivo draid2:8:1.
Desempeño DREAD, tolerancia a fallas y recuperación de la inversión
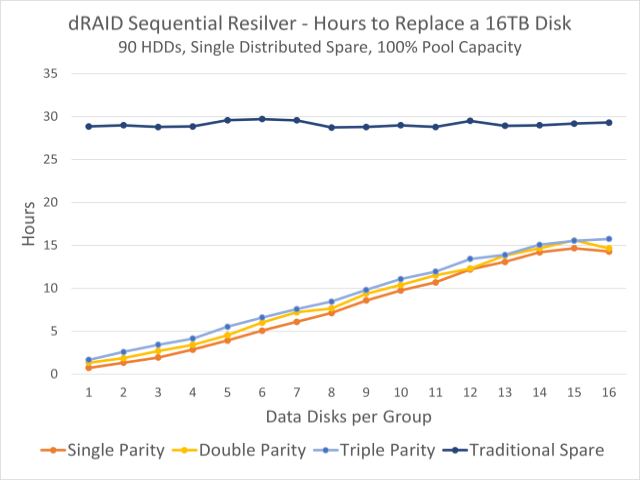
Este gráfico muestra los tiempos de reemergencia observados para un grupo de 90 discos. La línea azul oscuro en la parte superior es el tiempo de re-filtrado en un disco duro fijo; Las líneas coloreadas a continuación indican los tiempos de re-liquidación de la capacidad de reserva distribuida.
En su mayor parte, dRAID vdev funcionará de manera similar a un conjunto equivalente de vdev tradicionales, por ejemplo, draid1:2:0 En nueve discos, funcionará casi de manera equivalente a un conjunto de tres vdev RAIDz1 de ancho 3. La tolerancia a fallas también es similar: tiene la garantía de sobrevivir a una sola falla con p=1, al igual que con RAIDz1 vdevs.
Tenga en cuenta que dijimos que la tolerancia a fallas es similar, no eran idénticos. Solo se garantiza que un conjunto tradicional de tres vdev RAIDz1 de ancho 3 sobrevivirá a una falla de un solo disco, pero probablemente sobrevivirá a una falla de un solo disco, siempre que el segundo disco que falla no sea parte del mismo vdev que el primero, todo es bien.
en nueve discos draid1:2, una segunda falla en el disco casi seguramente mataría a vdev (y al paquete con él), Si Este fracaso ocurre antes de que sobrevivas. Dado que no hay conjuntos fijos de fuentes individuales, es muy probable que una segunda falla en el disco desactive sectores adicionales en fuentes ya degradadas, independientemente de Cual El segundo disco falló.
Esta falta de tolerancia a fallos se compensa de alguna manera con tiempos de recuperación exponencialmente más rápidos. En el gráfico en la parte superior de esta sección, podemos ver que en un lote de noventa discos de 16TB, está moviendo una máquina estacionaria convencional. spare No importa cómo configuremos dRAID vdev, lleva unas treinta horas, pero volver a aparecer en la redundancia distribuida puede tardar menos de una hora.
Esto se debe en gran parte al reformateo en una partición distribuida que divide la carga de escritura entre todos los discos restantes. Cuando lo usas en estilo tradicional spare, el disco de respaldo en sí es un cuello de botella: las lecturas provienen de todos los discos en vdev, pero todas las escrituras deben completarse con el respaldo. Pero cuando se rediseña la capacidad redundante distribuida, ambos se leen Y el Las cargas de trabajo de escritura se dividen entre todos los discos restantes.
Un dispositivo de recuperación distribuido también puede ser un dispositivo de recuperación en serie, en lugar de un procesador de resistencia, lo que significa que ZFS puede simplemente copiar todos los sectores afectados, sin preocuparse por qué. blocks Estos sectores pertenecen a. Por el contrario, los recuperadores de recuperación deben escanear todo el árbol de bloques, lo que da como resultado una carga de trabajo de lectura aleatoria, en lugar de una carga de trabajo de lectura secuencial.
Cuando se agrega el reemplazo físico del disco defectuoso al ensamblaje, esta reventa voluntad Es escalar, no secuencial, y ahogará el rendimiento de escritura de un disco de repuesto individual, en lugar de todo el vdev. Pero el tiempo para completar este proceso es mucho menos importante, porque vdev ni siquiera está en un estado de degradación.
Conclusiones
Las versiones distribuidas de RAID vdevs suelen estar destinadas a grandes servidores de almacenamiento: OpenZFS draid El diseño y las pruebas giraron en gran medida en torno a sistemas de 90 discos. A menor escala, los archivos vdevs tradicionales y spares Sigue siendo tan útil como antes.
Advertimos especialmente a los principiantes en almacenamiento que tengan cuidado con ellos. draid—Es un diseño significativamente más complejo que combinarlo con vdevs tradicionales. La flexibilidad rápida es excelente, pero draid Alcanza el éxito tanto en los niveles de estrés como en ciertos escenarios de rendimiento debido a sus líneas de longitud necesariamente fija.
Si bien los discos tradicionales continúan aumentando de tamaño sin aumentar significativamente el rendimiento, draid Su rápida reconfiguración puede resultar deseable incluso en sistemas más pequeños, pero llevará algún tiempo averiguar exactamente dónde comienza el punto ideal. Mientras tanto, recuerde que RAID no es una copia de seguridad; esto incluye draid!





